In the world of computer science and operating systems, process synchronization plays a critical role in ensuring that multiple processes can work together harmoniously without interfering with each other. In this blog post, we will delve into the concept of process synchronization, explore its types, and examine various synchronization algorithms that are used to achieve it.
What is Process Synchronization?
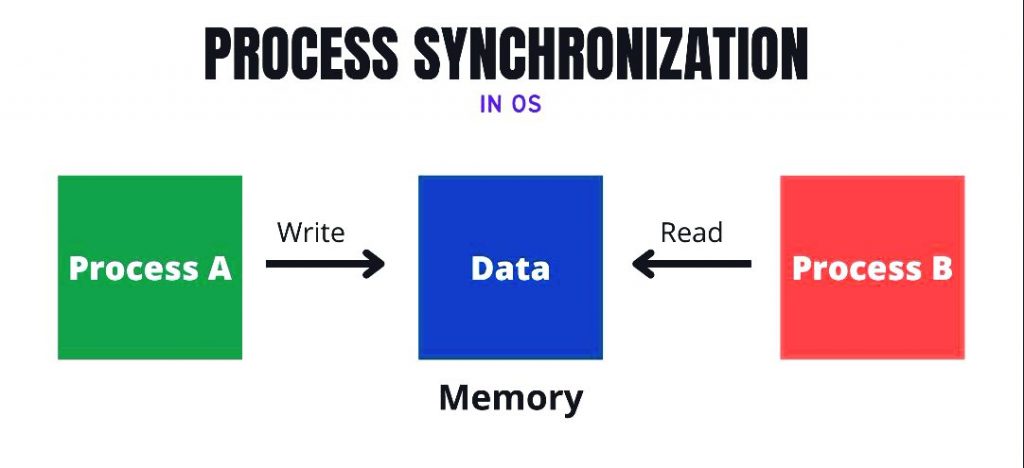
Process synchronization is a fundamental concept in computer science and operating systems. It refers to the coordination and management of multiple concurrent processes or threads to ensure they interact with shared resources or data in a controlled and orderly manner. The primary goal of process synchronization is to prevent issues such as data corruption, race conditions, and conflicts that can arise when multiple processes access shared resources simultaneously.
Process synchronization is essential for several reasons:
- Data Integrity: It ensures that shared data remains consistent and doesn’t get corrupted due to simultaneous access by multiple processes.
- Resource Allocation: It helps allocate resources effectively, ensuring that processes get the resources they need without causing contention.
- Orderly Execution: It maintains the order in which processes access shared resources, which is critical in scenarios like printing, database access, and more.
- Deadlock Avoidance: Process synchronization techniques help prevent and resolve deadlocks, which are situations where processes are stuck and unable to proceed.
The Need for Synchronization
The need for process synchronization arises from the concurrent execution of multiple processes. Without synchronization, processes can interfere with each other, leading to issues like:
- Race Conditions: These occur when two or more processes access shared data simultaneously, leading to unpredictable outcomes.
- Data Corruption: Simultaneous writes or improper reads can corrupt shared data.
- Deadlocks: Processes can get stuck in a state where they’re waiting for resources that are held by other processes, resulting in a deadlock.
Types of Process Synchronization
Process synchronization encompasses various types and problems:
- Mutual Exclusion: This type ensures that only one process at a time can access a shared resource. Mutex locks and semaphores are commonly used mechanisms to achieve mutual exclusion.
- Deadlock Prevention and Avoidance: These techniques aim to prevent and resolve deadlocks. Strategies include resource allocation graphs, Banker’s algorithm, and techniques to impose a specific resource allocation order.
- Producer-Consumer Problem: This classic synchronization problem involves a producer that produces data and a consumer that consumes it. Synchronization is required to ensure that the producer doesn’t overwrite unread data, and the consumer doesn’t read empty slots.
- Readers-Writers Problem: In this scenario, multiple readers can access a shared resource simultaneously, but exclusive access is needed for writing. Readers-writers locks help manage access to the resource.
- Dining Philosophers Problem: This is another classic synchronization problem that represents five philosophers sitting around a dining table. They alternate between thinking and eating while using forks. The challenge is to avoid deadlocks by ensuring that philosophers can only eat if they have both forks.
Each of these types of process synchronization presents unique challenges and requires different synchronization mechanisms and algorithms to ensure the orderly execution of concurrent processes and prevent issues like race conditions and deadlocks.
Synchronization Algorithms
Mutex (Mutual Exclusion): A mutex (short for mutual exclusion) is a synchronization primitive that ensures only one thread or process can access a shared resource at a time. It provides a way to protect critical sections of code from concurrent execution, preventing race conditions.
//C++ Code
#include <pthread.h>
pthread_mutex_t mutex;
void* threadFunction(void* arg) {
pthread_mutex_lock(&mutex); // Acquire the mutex
// Critical Section: Only one thread can execute this code at a time
pthread_mutex_unlock(&mutex); // Release the mutex
return NULL;
}
Semaphore: A semaphore is a synchronization construct that allows a specified number of threads to access a shared resource simultaneously. It can be used to control access to a resource based on available permits.
For example, Stocks trading software often uses semaphores to synchronize the processing of stock orders. A stock broker might use a semaphore to ensure that only one order can be processed at a time. This prevents race conditions and ensures that all orders are processed accurately.
// Python code
from threading import Semaphore, Thread
semaphore = Semaphore(2) # Allow 2 threads to access the resource simultaneously
def worker():
with semaphore:
# Critical Section: Up to 2 threads can execute this code concurrently
pass
Condition Variables: Condition variables are synchronization primitives used to coordinate threads or processes. They are often used in scenarios where a thread needs to wait for a certain condition to be met before proceeding.
// Java Code
import java.util.concurrent.locks.*;
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
void worker() {
lock.lock();
try {
while (conditionIsNotMet) {
condition.await(); // Wait until the condition is signaled
}
// Critical Section: Code execution after the condition is met
condition.signal(); // Signal other waiting threads
} finally {
lock.unlock();
}
}
Reader-Writer Locks: Reader-Writer locks are used in scenarios where multiple threads can read a shared resource concurrently, but exclusive access is required for writing. This allows for high concurrency in read-heavy workloads while maintaining data consistency.
//C++ Code
#include <iostream>
#include <mutex>
#include <shared_mutex>
std::shared_mutex rwLock;
void reader() {
std::shared_lock<std::shared_mutex> lock(rwLock);
// Read data (non-exclusive access)
}
void writer() {
std::unique_lock<std::shared_mutex> lock(rwLock);
// Write data (exclusive access)
}
Deadlock in Process Synchronization
Deadlock is a critical issue in process synchronization, occurring when two or more processes are unable to proceed because they are each waiting for the other to release a resource. This situation creates a standstill, where no progress can be made. Deadlocks are often a result of the following conditions:
- Mutual Exclusion: Processes must request exclusive access to resources, meaning that only one process can hold a resource at a time.
- Hold and Wait: Processes can hold resources while waiting for additional ones, which can lead to a circular waiting pattern.
- No Preemption: Resources cannot be forcibly taken away from a process. A process must release its resources voluntarily.
- Circular Wait: A cycle of processes exists, where each process is waiting for a resource held by another process in the cycle.
Strategies for Deadlock Prevention and Avoidance
1. Prevention: These strategies focus on eliminating one or more of the conditions necessary for deadlock to occur.
a. Mutual Exclusion Control: Ensure that not all resources are exclusively allocated. Some resources can be shared.
b. Hold and Wait Prevention: Require processes to request all the resources they need at once, or release acquired resources if the complete set cannot be obtained.
c. No Preemption: Allow resources to be preempted if necessary. This involves forcibly taking resources from a process and allocating them to another.
d. Circular Wait Prevention: Impose a total order on resources, requiring processes to request resources in a specific sequence.
2. Avoidance: These strategies involve carefully managing resource allocation to avoid the possibility of a deadlock.
a. Resource Allocation Graph: Maintain a graph that tracks resource allocation and request relationships. Before allocating a resource, check if it creates a cycle in the graph, which would indicate a potential deadlock.
3. Detection and Recovery: Rather than preventing or avoiding deadlocks, these strategies identify when a deadlock has occurred and take corrective action. Recovery might involve terminating one or more processes to break the deadlock.
Banker's Algorithm:
The Banker’s Algorithm is a well-known technique for deadlock avoidance. It works by ensuring that resource allocations never result in unsafe states where a deadlock could occur. Here’s a simple Python implementation of the Banker’s Algorithm:
// C++ Code
#include <iostream>
#include <vector>
using namespace std;
// Define the number of processes and resources
const int NUM_PROCESSES = 5;
const int NUM_RESOURCES = 3;
// Function to check if the system is in a safe state
bool isSafe(vector<int>& available, vector<vector<int>>& max, vector<vector<int>>& allocation) {
vector<int> work(available);
vector<bool> finish(NUM_PROCESSES, false);
for (int i = 0; i < NUM_PROCESSES; ++i) {
if (!finish[i]) {
bool canAllocate = true;
for (int j = 0; j < NUM_RESOURCES; ++j) {
if (max[i][j] - allocation[i][j] > work[j]) {
canAllocate = false;
break;
}
}
if (canAllocate) {
// Release allocated resources and mark the process as finished
finish[i] = true;
for (int j = 0; j < NUM_RESOURCES; ++j) {
work[j] += allocation[i][j];
}
// Start over, check from the beginning
i = -1;
}
}
}
// If all processes are marked as finished, the system is in a safe state
for (bool f : finish) {
if (!f) {
return false;
}
}
return true;
}
int main() {
// Define available resources
vector<int> available = {3, 3, 2};
// Define the maximum demand of each process
vector<vector<int>> max = {
{7, 5, 3},
{3, 2, 2},
{9, 0, 2},
{2, 2, 2},
{4, 3, 3}
};
// Define the resources currently allocated to each process
vector<vector<int>> allocation = {
{0, 1, 0},
{2, 0, 0},
{3, 0, 2},
{2, 1, 1},
{0, 0, 2}
};
if (isSafe(available, max, allocation)) {
cout << "System is in a safe state." << endl;
} else {
cout << "System is in an unsafe state; deadlock may occur." << endl;
}
return 0;
}